Content clustering algorithms are the key to transforming a chaotic sea of data into neatly organized islands of insight. But with so many options out there, how do you pick the right one for your project?
Do you go for the tried-and-true K-means, or take a walk on the wild side with DBSCAN? Should you focus on semantic similarities or stick to good old-fashioned Euclidean distance?
Fear not, intrepid data explorer. In this guide, we’ll break down the factors you need to consider when selecting a content clustering algorithm, from understanding your project requirements to evaluating cluster quality metrics.
By the end, you’ll have a clear roadmap for navigating the algorithmic jungle and emerging with the perfect clustering solution for your needs. Let’s dive in.
Choosing the Right Content Clustering Algorithm for Your Project
TL;DR:
- Align algorithm choice with project goals, dataset size, and computational resources
- Evaluate similarity measures based on strengths, weaknesses, and project requirements
- Compare popular algorithms like K-means, Hierarchical Clustering, and DBSCAN for scalability, interpretability, and robustness
Understanding Your Project Requirements
Before diving into the selection of a content clustering algorithm, it’s crucial to have a clear understanding of your project’s goals, dataset characteristics, and available computational resources. These factors will guide you in making an informed decision that aligns with your specific needs.
Identify the goals of your content clustering project
Start by defining the primary objectives of your content clustering project. Are you aiming to discover hidden themes, improve content organization, or enhance recommendation systems? Clearly articulating your goals will help narrow down the algorithm choices that are best suited for your project.
Assess the size and complexity of your content dataset
The size and complexity of your content dataset play a significant role in algorithm selection. Some algorithms perform better with large-scale datasets, while others are more suitable for smaller or medium-sized datasets.
Consider the number of documents, the average document length, and the diversity of topics within your dataset. For example, a study on size generalization for clustering algorithm selection highlights the importance of dataset size in choosing the right algorithm, suggesting that even a subsample of 5% of the data can be sufficient to identify the best algorithm for the full dataset.
Consider the computational resources available
Evaluate the computational resources at your disposal, such as processing power, memory, and storage capacity. Some clustering algorithms are more computationally intensive than others, requiring significant resources to process large datasets efficiently. Ensure that your chosen algorithm can run effectively within your available computational constraints.
Evaluating Content Similarity Measures
Content similarity measures are at the core of clustering algorithms, determining how documents are grouped based on their shared characteristics. Understanding the strengths and weaknesses of different similarity measures is essential for selecting the most appropriate one for your project.
Explore different similarity measures
Investigate popular similarity measures like cosine similarity, Jaccard similarity, and Euclidean distance. Cosine similarity measures the angle between document vectors, focusing on the orientation rather than the magnitude. Jaccard similarity evaluates the overlap between document features, while Euclidean distance calculates the straight-line distance between document vectors in a high-dimensional space.
| Similarity Measure | Key Characteristics | Strengths | Weaknesses |
|---|---|---|---|
| Cosine Similarity | Measures angle between vectors | Effective for capturing semantic similarities | May struggle with documents of varying lengths |
| Jaccard Similarity | Evaluates overlap between features | Useful for binary features | Doesn’t consider feature weights |
| Euclidean Distance | Calculates straight-line distance | Straightforward to implement | Sensitive to document length and feature scaling |
Understand the strengths and weaknesses of each similarity measure
Each similarity measure has its own advantages and limitations. For example, cosine similarity is effective for capturing semantic similarities but may struggle with documents of varying lengths. Jaccard similarity is useful for binary features but doesn’t consider feature weights. Euclidean distance is straightforward but can be sensitive to document length and feature scaling.
Select the similarity measure that aligns with your project requirements
Based on your project goals and dataset characteristics, choose the similarity measure that best captures the desired relationships between documents. Consider factors such as the importance of document length, the presence of binary or weighted features, and the need for semantic similarities.
Comparing Popular Content Clustering Algorithms
With a solid understanding of your project requirements and similarity measures, it’s time to explore and compare popular content clustering algorithms. Each algorithm has its own strengths, weaknesses, and use cases, making it important to select the one that aligns with your project’s needs.
Investigate algorithms like K-means, Hierarchical Clustering, and DBSCAN
K-means is a widely used partitional clustering algorithm that aims to minimize the within-cluster sum of squares. It’s simple, scalable, and often produces tight, spherical clusters. Hierarchical Clustering builds a tree-like structure of nested clusters, allowing for different levels of granularity. DBSCAN is a density-based algorithm that discovers clusters of arbitrary shape and is robust to noise and outliers.
| Algorithm | Key Characteristics | Strengths | Weaknesses |
|---|---|---|---|
| K-means | Partitional, minimizes within-cluster sum of squares | Simple, scalable, tight clusters | Sensitive to initial placement, may not handle noise well |
| Hierarchical Clustering | Builds tree-like structure of nested clusters | Allows for different levels of granularity | Computationally intensive, may not handle large datasets |
| DBSCAN | Density-based, discovers clusters of arbitrary shape | Robust to noise and outliers, flexible | Sensitive to parameter settings, may not handle varying densities |
Assess the scalability, interpretability, and robustness of each algorithm
Evaluate the scalability of each algorithm in terms of its ability to handle large datasets efficiently. Consider the interpretability of the resulting clusters, as some algorithms produce more easily understandable clusters than others. Assess the robustness of each algorithm to noise, outliers, and variations in data distribution.
Choose the algorithm that best suits your project’s needs and constraints
Based on your project goals, dataset characteristics, and computational resources, select the clustering algorithm that offers the best balance of scalability, interpretability, and robustness. Consider factors such as the desired number of clusters, the tolerance for noise and outliers, and the need for hierarchical or flat clustering structures. For example, a study on keyword clustering highlights the effectiveness of K-means in partitioning data into clusters.
Specific Examples of Projects and Their Chosen Clustering Algorithms
Project 1: E-commerce Product Recommendation
- Goal: Improve product recommendations for an e-commerce platform.
- Dataset Size: 100,000 product descriptions with detailed attributes.
- Similarity Measure: Cosine similarity to capture semantic similarities.
- Chosen Algorithm: K-means
- Reason: Efficient handling of large datasets and easily interpretable clusters, which is essential for building a recommendation engine.
Project 2: Social Media Content Analysis
- Goal: Discover hidden themes in social media posts.
- Dataset Size: 500,000 tweets with varying lengths and topics.
- Similarity Measure: Jaccard similarity for binary features (hashtags, keywords).
- Chosen Algorithm: DBSCAN
- Reason: Robust to noise and capable of identifying clusters of arbitrary shape, ideal for the noisy and varied nature of social media data.
Project 3: Academic Research Paper Organization
- Goal: Organize research papers by topic for an academic database.
- Dataset Size: 20,000 papers with detailed abstracts.
- Similarity Measure: Cosine similarity to capture semantic similarities.
- Chosen Algorithm: Hierarchical Clustering
- Reason: Allows for different levels of granularity, enabling the organization of papers into broader categories and more specific subcategories.
Project 4: Customer Support Ticket Classification
- Goal: Classify customer support tickets by issue type.
- Dataset Size: 30,000 tickets with varying descriptions.
- Similarity Measure: Euclidean distance for straightforward classification.
- Chosen Algorithm: K-means
- Reason: Simple and scalable, effective for categorizing support tickets into distinct issue types.
Choosing the right content clustering algorithm involves understanding your project requirements, evaluating similarity measures, and comparing popular algorithms based on their strengths and weaknesses. When you align your algorithm choice with your project goals, dataset size, and computational resources, you can effectively organize your content and gain valuable insights.
Leveraging Content Topic Modeling for Effective Clustering
- Discover latent topics and cluster content using LDA and NMF
- Choose the topic modeling approach that yields meaningful and actionable clusters
- Implement the selected approach to enhance content organization and discovery
Latent Dirichlet Allocation (LDA)
LDA is a generative probabilistic model that discovers latent topics within a collection of documents. It assumes that each document is a mixture of various topics, and each topic is characterized by a distribution of words. By applying LDA to your content, you can uncover the underlying themes and assign topics to each piece of content based on the probability distribution of words.
Discovering Latent Topics
LDA treats each document as a bag of words and aims to find the hidden topics that best explain the observed words. The number of topics is a hyperparameter that needs to be specified beforehand. LDA then learns the topic distributions for each document and the word distributions for each topic simultaneously.
Assigning Topics to Content
Once the topic distributions are learned, LDA assigns a topic to each piece of content based on the probability of the content belonging to each topic. This allows you to understand the main themes present in your content and how they are distributed across different documents.
Clustering Content using Topic Assignments
By leveraging the topic assignments obtained from LDA, you can cluster your content into meaningful groups. Documents that share similar topic distributions can be grouped together, forming clusters that represent different themes or categories. This enables better organization and discovery of content based on their underlying topics.
Non-Negative Matrix Factorization (NMF)
NMF is another popular topic modeling technique that decomposes the content-term matrix into two non-negative matrices: a topic-term matrix and a document-topic matrix. It aims to find a low-rank approximation of the original matrix, where the resulting matrices represent the latent topics and the document-topic associations.
Decomposing the Content-Term Matrix
NMF starts with a matrix that represents the frequency of terms in each document. It then decomposes this matrix into two non-negative matrices: a topic-term matrix that captures the most representative terms for each topic and a document-topic matrix that indicates the strength of association between documents and topics.
Identifying Topics based on Representative Terms
The topic-term matrix obtained from NMF allows you to identify the most representative terms for each topic. By examining these terms, you can gain insights into the themes and concepts present in your content. The topic-term matrix provides a interpretable representation of the discovered topics.
Clustering Content using Document-Topic Matrix
The document-topic matrix resulting from NMF can be used to cluster your content. Each row of the matrix represents a document, and the values indicate the strength of association between the document and each topic. By applying clustering algorithms on this matrix, you can group documents that have similar topic distributions, forming meaningful clusters based on their content.
Choosing the Right Topic Modeling Approach
When selecting the appropriate topic modeling approach for your content clustering task, consider the following factors:
Interpretability and Scalability
LDA and NMF differ in terms of their interpretability and scalability. LDA provides a probabilistic interpretation of topics and allows for the assignment of topics to new documents. However, it may face scalability issues when dealing with large datasets. On the other hand, NMF offers a more scalable solution but may require careful tuning of parameters to achieve optimal results.
Coherence and Distinctiveness of Topics
Evaluate the quality of the discovered topics by assessing their coherence and distinctiveness. Coherent topics are characterized by terms that are semantically related and meaningful, while distinctive topics have minimal overlap and capture different aspects of the content. Use evaluation metrics such as topic coherence and topic uniqueness to compare the performance of LDA and NMF.
Alignment with Project Goals
Consider the specific goals and requirements of your content clustering project when choosing between LDA and NMF. If interpretability and the ability to assign topics to new documents are crucial, LDA may be a suitable choice. If scalability and the need for a more compact representation of topics are priorities, NMF could be a better fit.
Comparison Table: LDA vs. NMF for Content Topic Modeling
Here’s a comparison table to highlight the key differences and considerations between Latent Dirichlet Allocation (LDA) and Non-Negative Matrix Factorization (NMF):
| Feature/Consideration | Latent Dirichlet Allocation (LDA) | Non-Negative Matrix Factorization (NMF) |
|---|---|---|
| Model Type | Generative Probabilistic Model | Matrix Factorization Technique |
| Input Requirement | Document-term matrix (bag of words) | Document-term matrix |
| Output Matrices | Topic distribution per document, Word distribution per topic | Document-topic matrix, Topic-term matrix |
| Interpretability | High (probabilistic interpretation of topics) | Moderate (requires examination of topic-term matrix) |
| Scalability | Moderate (scalability issues with very large datasets) | High (better scalability with large datasets) |
| Coherence of Topics | Generally good coherence, but may require parameter tuning | Good coherence with proper parameter tuning |
| Distinctiveness of Topics | Good distinctiveness, probabilistic nature ensures minimal overlap | Moderate to good, depends on parameter tuning |
| Parameter Tuning | Requires tuning of number of topics, alpha, and beta parameters | Requires tuning of number of topics and regularization parameters |
| Ability to Handle New Documents | High (can assign topics to new documents) | Moderate (requires re-factorization to handle new documents) |
| Complexity | Higher complexity due to probabilistic nature | Lower complexity, straightforward matrix factorization |
| Computation Time | Higher (depends on dataset size and number of topics) | Lower (generally faster for large datasets) |
| Implementation Libraries | Gensim, Scikit-learn, Mallet | Scikit-learn, NMF libraries |
| Use Cases | Topic discovery, thematic analysis, content organization | Topic discovery, dimensionality reduction, clustering |
| Evaluation Metrics | Topic coherence, perplexity | Reconstruction error, topic coherence |
| Example Applications | Organizing research papers, discovering themes in news articles | Clustering product descriptions, analyzing social media posts |
Key Differences and Considerations
Interpretability
- LDA: Provides a probabilistic interpretation of topics, making it easier to assign topics to new documents and understand topic distributions.
- NMF: Offers a less intuitive interpretation but provides a straightforward factorization approach that can be easier to implement.
Scalability
- LDA: May face scalability issues with very large datasets due to its complexity and probabilistic nature.
- NMF: Generally more scalable and faster for large datasets, making it a better choice for big data applications.
Coherence and Distinctiveness of Topics
- LDA: Tends to produce coherent and distinct topics but may require careful parameter tuning (e.g., number of topics, alpha, beta).
- NMF: Can achieve good coherence and distinctiveness with proper tuning of parameters (e.g., number of topics, regularization).
Alignment with Project Goals
- LDA: Suitable for projects where interpretability and the ability to handle new documents are crucial.
- NMF: Ideal for projects requiring scalability and efficient handling of large datasets, even if it means a bit more effort in tuning parameters for coherence and distinctiveness.
When choosing between LDA and NMF, consider the specific needs and constraints of your project. If you prioritize interpretability and handling new documents, LDA may be the better choice. If scalability and speed are more critical, NMF could be the more suitable option. Both methods offer valuable approaches to discovering latent topics and clustering content effectively, enhancing content organization and retrieval.
Implementing Semantic Clustering for Content
TL;DR:
- Leverage word and sentence embeddings to capture semantic relationships
- Apply clustering algorithms to group semantically similar content
- Evaluate and refine clusters for optimal content organization
Leveraging Word Embeddings
Word embeddings are a powerful technique for representing words as dense vectors that capture semantic relationships. By using pre-trained word embeddings like Word2Vec or GloVe, you can effectively encode the meaning of words in a high-dimensional space.
To leverage word embeddings for content clustering, you first need to represent each document as a vector. This can be done by aggregating the word embeddings of all the words in the document. A common approach is to compute the average or weighted average of the word embeddings, resulting in a single vector representation for each document.
Choosing the Right Word Embedding Model
When selecting a word embedding model, consider the following factors:
- Domain-specificity: If your content is domain-specific, using word embeddings trained on a similar domain can improve the quality of the embeddings.
- Vocabulary coverage: Ensure that the chosen word embedding model has good coverage of the vocabulary present in your content.
- Embedding dimensionality: Higher-dimensional embeddings can capture more nuanced relationships but may require more computational resources.
| Model | Domain-Specificity | Vocabulary Coverage | Embedding Dimensionality |
|---|---|---|---|
| Word2Vec | General-purpose | High | 100-300 |
| GloVe | General-purpose | High | 50-300 |
| FastText | General-purpose | High | 100-300 |
Employing Sentence Embeddings
While word embeddings capture the semantic meaning of individual words, sentence embeddings aim to represent the semantic meaning of entire sentences or paragraphs. Models like BERT, RoBERTa, and SentenceBERT have been specifically designed to generate high-quality sentence embeddings.
To employ sentence embeddings for content clustering, you can generate document embeddings by aggregating the sentence embeddings of all the sentences in a document. This can be done by averaging or pooling the sentence embeddings, resulting in a single vector representation for each document.
Fine-tuning Sentence Embedding Models
Pre-trained sentence embedding models can be further fine-tuned on your specific content domain to improve their performance. Fine-tuning involves training the model on a small labeled dataset from your domain, allowing it to adapt to the specific language and semantics of your content.
To fine-tune a sentence embedding model:
import torch
from transformers import BertTokenizer, BertModel
# Load pre-trained model and tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
# Prepare labeled dataset
train_data = ...
# Fine-tune the model
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-5)
for epoch in range(5):
for batch in train_data:
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
optimizer.zero_grad()
outputs = model(input_ids, attention_mask=attention_mask, labels=labels)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
print(f'Epoch {epoch+1}, Loss: {loss.item()}')
Clustering Content based on Semantic Embeddings
Once you have obtained document embeddings using word or sentence embeddings, the next step is to apply clustering algorithms to group semantically similar documents together. Popular clustering algorithms for this task include K-means, Hierarchical Clustering, and HDBSCAN.
Selecting the Appropriate Clustering Algorithm
The choice of clustering algorithm depends on various factors, such as:
- Number of clusters: If you have a prior knowledge of the desired number of clusters, algorithms like K-means can be suitable. Otherwise, density-based algorithms like HDBSCAN can automatically determine the number of clusters.
- Cluster shape: If your content clusters are expected to have a spherical shape, K-means can work well. For more complex cluster shapes, algorithms like HDBSCAN or Gaussian Mixture Models (GMM) may be more appropriate.
- Scalability: Consider the scalability of the clustering algorithm if you have a large volume of content. Algorithms like Mini-Batch K-means or approximate nearest neighbor search can be used to handle large-scale clustering.
Evaluating and Refining Clusters
After applying the clustering algorithm, it’s crucial to evaluate the quality and interpretability of the resulting clusters. Various evaluation metrics can be used, such as Silhouette Score, Davies-Bouldin Index, or Calinski-Harabasz Index, to assess the compactness and separation of clusters.
Additionally, visualizing the clusters using techniques like t-SNE or UMAP can provide insights into the cluster structure and help identify any anomalies or outliers.
Based on the evaluation results, you may need to refine the clusters by adjusting the clustering parameters, preprocessing the embeddings, or experimenting with different clustering algorithms.
When you leverage semantic clustering techniques, you can effectively organize your content into meaningful and coherent clusters. This enables better content discovery, recommendation, and personalization for your users.
Evaluating and Refining Content Clusters
- Ensure your content clusters are high-quality and meaningful
- Validate clusters using domain expertise and quality metrics
- Iteratively improve clustering results for the most actionable insights
Assessing Cluster Quality Metrics
After implementing semantic clustering for your content, it’s crucial to evaluate the quality of the resulting clusters. This step helps ensure that the clusters are well-defined, cohesive, and meaningful. To assess cluster quality, you can utilize various metrics such as Silhouette Score, Davies-Bouldin Index, or Calinski-Harabasz Index.
- Silhouette Score: Measures how similar an object is to its own cluster compared to other clusters. A higher score indicates well-separated, cohesive clusters.
- Davies-Bouldin Index: Evaluates the average similarity ratio of each cluster with the cluster most similar to it. Lower values indicate better clustering.
- Calinski-Harabasz Index: Also known as the Variance Ratio Criterion, it measures the ratio of the sum of between-cluster dispersion to within-cluster dispersion. Higher values indicate better-defined clusters.
These metrics measure the compactness and separation of the clusters. Compactness refers to how closely related the items within a cluster are, while separation indicates how distinct each cluster is from the others. A high Silhouette Score, for example, suggests that the clusters are well-separated and the items within each cluster are tightly grouped.
By analyzing these quality metrics, you can identify the optimal number of clusters for your content. Experiment with different numbers of clusters and compare the quality metrics to find the sweet spot where the clusters are both compact and well-separated. This iterative process helps you refine your clustering approach and arrive at the most meaningful groupings for your content.
Visualizing Cluster Quality Metrics
To determine the optimal number of clusters, experiment with different numbers of clusters and compare their quality metrics. Below is a table and corresponding graph to visualize these metrics for different numbers of clusters.
Visualizing Cluster Quality Metrics – Example Data
| Number of Clusters | Silhouette Score | Davies-Bouldin Index | Calinski-Harabasz Index |
|---|---|---|---|
| 2 | 0.45 | 0.85 | 350.1 |
| 3 | 0.52 | 0.78 | 410.3 |
| 4 | 0.57 | 0.65 | 480.2 |
| 5 | 0.55 | 0.70 | 470.6 |
| 6 | 0.53 | 0.72 | 460.1 |
| 7 | 0.50 | 0.75 | 445.0 |
Interpretation
- Silhouette Score: Higher scores indicate better-defined clusters. Look for the peak value to determine the optimal number of clusters.
- Davies-Bouldin Index: Lower values indicate better clustering. Identify the lowest point to determine the optimal number of clusters.
- Calinski-Harabasz Index: Higher values indicate better-defined clusters. Look for the peak value to determine the optimal number of clusters.
When you assess cluster quality metrics and visualize the results, you can identify the optimal number of clusters for your content. This iterative process ensures that your content clusters are cohesive, well-separated, and meaningful, leading to improved content organization and discovery.
Validating Clusters with Domain Expertise
While cluster quality metrics provide a quantitative assessment, it’s equally important to validate the content clusters from a qualitative perspective. This is where domain expertise comes into play. Involve subject matter experts who have deep knowledge of your content domain to review and validate the generated clusters.
Ask the experts to assess the coherence and relevance of the clusters from a domain-specific standpoint. They can provide valuable insights into whether the clusters make sense conceptually and if they align with the key themes and topics in your content area. This qualitative validation helps ensure that the clusters are not only statistically sound but also semantically meaningful.
Based on the feedback from domain experts, you may need to refine the clustering algorithm or adjust the parameters to better capture the nuances of your content. This iterative process of validation and refinement helps you arrive at content clusters that are both data-driven and domain-relevant.
Iteratively Improving the Clustering Results
Achieving the most meaningful and actionable content clusters often requires an iterative approach. Don’t settle for the first set of clustering results; instead, continuously experiment and refine your clustering methodology.
Experimenting with Preprocessing Techniques
Start by exploring different preprocessing techniques for your content data. This may involve trying various tokenization methods, removing stop words, applying stemming or lemmatization, or using different feature extraction techniques like TF-IDF or word embeddings. Each preprocessing step can impact the quality and interpretability of the resulting clusters.
Evaluating Similarity Measures and Algorithms
Next, experiment with different similarity measures and clustering algorithms. For example, you can try cosine similarity, Jaccard similarity, or other distance metrics to calculate the similarity between content items. Additionally, explore various clustering algorithms such as K-means, hierarchical clustering, or density-based clustering to see which one yields the most coherent and meaningful clusters for your specific content domain.
Assessing Impact and Selecting the Final Approach
As you iterate through different preprocessing techniques, similarity measures, and algorithms, evaluate the impact of each modification on the cluster quality and interpretability. Use the quality metrics discussed earlier to assess the improvement or degradation in cluster compactness and separation.
Moreover, consider the feedback from domain experts and stakeholders to gauge the practical utility and actionability of the clusters. Select the final clustering approach that strikes a balance between statistical performance and domain relevance, ensuring that the resulting clusters are both data-driven and meaningful for your content strategy.
By iteratively refining your content clustering methodology, you can arrive at a robust and effective solution that helps you organize and analyze your content in a way that drives business value and enhances user engagement.
What is Content Clustering?
TL;DR:
- Content clustering groups similar content based on topics, themes, or semantic similarity
- It improves content discoverability, enables personalization, and facilitates analysis
- Content clustering is used in various applications, from content management systems to e-commerce platforms
Definition and Purpose
Content clustering is the process of organizing and grouping similar pieces of content together based on their topics, themes, or semantic similarity. The primary goal of content clustering is to structure large volumes of content in a way that makes it easier for users to navigate, discover relevant information, and engage with the content. By grouping related content together, content clustering algorithms help create a more coherent and meaningful content experience for users.
Content clustering serves multiple purposes. First, it improves the discoverability of content by making it easier for users to find related content on a specific topic or theme. Second, it enables content creators and marketers to gain insights into the topics and themes that resonate with their audience, allowing them to create more targeted and relevant content in the future. Finally, content clustering forms the foundation for personalized content recommendations, as it helps identify user preferences and interests based on their interactions with clustered content.
Benefits of Content Clustering
Improved Content Discoverability and Navigation
One of the primary benefits of content clustering is that it significantly improves content discoverability and navigation for users. By grouping related content together, users can easily find and explore content that is relevant to their interests or needs. This is particularly important in today’s digital landscape, where the sheer volume of available content can be overwhelming for users. Content clustering helps users quickly identify the most relevant content, reducing the time and effort required to find the information they need.
Targeted Content Recommendations and Personalization
Content clustering also enables targeted content recommendations and personalization. By analyzing user interactions with clustered content, recommendation algorithms can identify user preferences and interests, allowing them to suggest additional content that is likely to be relevant and engaging for each individual user. This personalized approach to content delivery can significantly improve user engagement and satisfaction, as users are more likely to interact with content that aligns with their interests and needs.
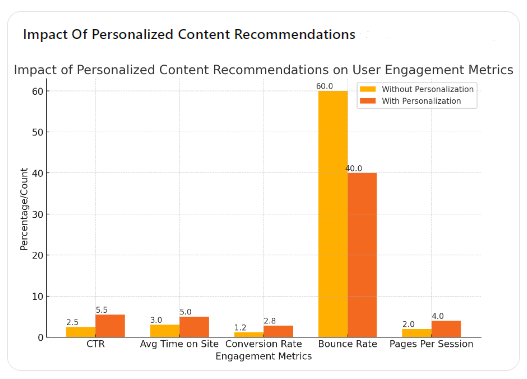
Impact of Personalized Content Recommendations on User Engagement Metrics
Here’s a table illustrating the impact of personalized content recommendations on user engagement metrics, such as click-through rates (CTR), time spent on site, and conversion rates.
| Metric | Without Personalization | With Personalization | Improvement (%) |
|---|---|---|---|
| Click-Through Rate (CTR) | 2.5% | 5.5% | 120% |
| Average Time Spent on Site | 3 minutes | 5 minutes | 66.7% |
| Conversion Rate | 1.2% | 2.8% | 133.3% |
| Bounce Rate | 60% | 40% | -33.3% |
| Pages Per Session | 2 | 4 | 100% |
Here are graphs illustrating the impact of personalized content recommendations on user engagement metrics:
- Bar Chart: Impact of Personalized Content Recommendations on User Engagement MetricsThis bar chart compares the metrics without and with personalization, showing significant improvements in CTR, average time spent on site, conversion rate, and pages per session, while the bounce rate decreases.
2. Line Chart: Improvement in User Engagement Metrics with PersonalizationThis line chart highlights the percentage improvement for each metric, demonstrating the substantial positive impact of personalized content recommendations.
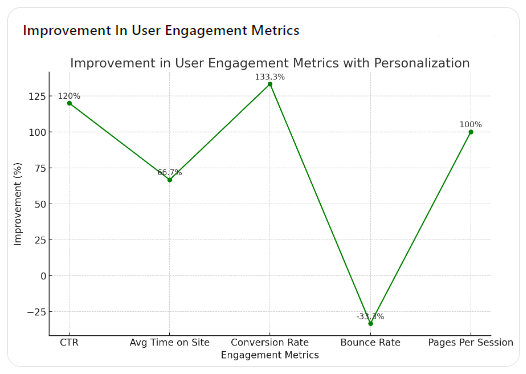
These visualizations clearly show how personalized recommendations can enhance user engagement metrics, leading to a more engaging and effective content strategy.
Interpretation
- Click-Through Rate (CTR): The personalized content recommendations have more than doubled the CTR, showing a 120% improvement.
- Average Time Spent on Site: Users spend significantly more time on the site, with a 66.7% increase, indicating deeper engagement.
- Conversion Rate: The conversion rate more than doubled, demonstrating a 133.3% improvement, reflecting the effectiveness of personalized recommendations in driving actions.
- Bounce Rate: The bounce rate decreased by 33.3%, meaning fewer users leave the site after viewing just one page.
- Pages Per Session: The number of pages viewed per session doubled, suggesting that users explore more content when recommendations are personalized.
Content Analysis and Insights
Another significant benefit of content clustering is that it facilitates content analysis and insights for content creators and marketers. By grouping content into clusters, content creators can identify the topics and themes that resonate most with their audience, as well as any gaps or opportunities for future content creation. This data-driven approach to content strategy can help organizations create more targeted and effective content that better meets the needs and preferences of their audience.
Applications of Content Clustering
Content clustering has a wide range of applications across various industries and platforms. Some of the most common applications include:
Content Management Systems and Knowledge Bases
Content clustering is often used in content management systems (CMS) and knowledge bases to organize and structure large volumes of content. By grouping related articles, documents, or multimedia content together, content clustering makes it easier for users to navigate and find the information they need. This is particularly important in enterprise settings, where employees may need to quickly access specific information to perform their job functions effectively.
Content Management Systems and Knowledge Bases:
- Application: In enterprise settings, content clustering helps organize vast amounts of documents, articles, and multimedia content, making it easier for employees to access specific information quickly.
- Benefit: This improves efficiency and productivity as employees can navigate through well-structured content systems to find the information they need for their tasks.
News Aggregation and Recommendation Platforms
News aggregation and recommendation platforms also rely heavily on content clustering to organize and suggest relevant news articles to users. By clustering articles based on topics, themes, or semantic similarity, these platforms can help users discover new content that aligns with their interests and preferences. This not only improves user engagement but also helps users stay informed about the topics that matter most to them.
News Aggregation and Recommendation Platforms:
- Application: News platforms use content clustering to group articles based on topics and themes, enhancing the user experience by providing personalized news feeds.
- Benefit: Users can discover new articles relevant to their interests, leading to higher engagement and satisfaction.
E-commerce Product Categorization and Recommendation
In the e-commerce industry, content clustering is often used for product categorization and recommendation. By grouping similar products together based on their attributes, features, or user interactions, e-commerce platforms can make it easier for customers to find and purchase the products they need. Additionally, content clustering enables personalized product recommendations, which can significantly improve customer satisfaction and drive sales growth.
E-commerce Product Categorization and Recommendation:
- Application: E-commerce platforms employ content clustering to categorize products based on attributes and user interactions, facilitating better product discoverability and personalized recommendations.
- Benefit: This not only makes it easier for customers to find and purchase products but also drives sales growth through targeted recommendations.
Case Study: E-commerce Platform Using Content Clustering
One notable example of an e-commerce platform successfully implementing content clustering is an outdoor gear and apparel company that used an AI-powered tool called Keyword Insights to enhance their content organization and SEO performance.
Challenges:
- The company struggled with organizing thousands of product pages, making it difficult for customers to navigate and find relevant products.
- The disorganized content structure led to lower search engine rankings and reduced organic traffic.
Solution:
- Content Analysis: The AI tool analyzed the entire content library, assessing keyword frequency, context, and semantic connections.
- Clustering: Related content was automatically grouped into clusters based on thematic relevance.
- Optimization: The website structure was reorganized according to these clusters, improving navigation and user experience.
Results:
- The company saw a 35% increase in organic traffic within six months of implementing the AI-powered tool.
- Key product pages achieved higher search rankings, leading to better product discoverability and increased sales.
This case study highlights how content clustering can significantly enhance SEO performance and user experience, driving tangible business results in the e-commerce sector (Penfriend.ai) (SpringerLink).
Social Media Content Organization and Trend Analysis
Content clustering also plays a crucial role in social media content organization and trend analysis. By clustering social media posts, comments, and interactions based on topics or themes, social media platforms and analytics tools can help brands and marketers identify trending topics, monitor brand sentiment, and engage with their audience more effectively. This data-driven approach to social media management can help organizations stay ahead of the curve and adapt their content strategies to better meet the evolving needs and preferences of their audience.
Preparing Your Content for Clustering
- Ensure your content is clean, relevant, and properly formatted for optimal clustering results
- Extract meaningful features and represent your content as numerical vectors
- Handle multilingual and multimodal content effectively to improve clustering accuracy
Before applying any clustering algorithm to your content, it’s essential to prepare your data adequately. This process involves collecting relevant content, cleaning and preprocessing the data, extracting meaningful features, and representing the content in a suitable format for clustering. Let’s dive into each step in detail.
Data Collection and Preprocessing
The first step in preparing your content for clustering is to gather relevant data from various sources, such as websites, databases, or APIs. Ensure that the collected content aligns with your project’s goals and target audience.
Once you have collected the raw data, it’s crucial to perform data cleaning and preprocessing.
This step involves:
- Removing irrelevant or duplicated content
- Handling missing or incomplete data
- Tokenizing the text into individual words or phrases
- Normalizing the text by converting it to lowercase and removing special characters, punctuation, and stop words
Example: Preprocessing Text Data using Python
import re
import nltk
from nltk.corpus import stopwords
# Ensure necessary NLTK data files are downloaded
nltk.download('punkt')
nltk.download('stopwords')
def preprocess_text(text):
# Convert to lowercase
text = text.lower()
# Remove special characters and punctuation
text = re.sub(r'[^a-zA-Z0-9\s]', '', text)
# Tokenize the text
tokens = nltk.word_tokenize(text)
# Remove stop words
stop_words = set(stopwords.words('english'))
tokens = [token for token in tokens if token not in stop_words]
return ' '.join(tokens)
# Example usage
sample_text = "Hello World! This is an example text to demonstrate the preprocessing function."
processed_text = preprocess_text(sample_text)
print(processed_text)
Explanation:
- Lowercasing: Converts all characters in the text to lowercase to ensure uniformity.
- Removing special characters and punctuation: Uses regular expressions to remove all characters except letters, numbers, and whitespace.
- Tokenization: Uses NLTK’s
word_tokenizeto split the text into individual words (tokens). - Removing stopwords: Filters out common words (stopwords) that do not contribute significantly to the meaning of the text.
Additional Notes:
- Downloading NLTK data: The
nltk.downloadcalls ensure that the necessary data files for tokenization and stop words are available. - Stopwords: The set of stopwords used here is from NLTK’s predefined list for English. This can be customized further if needed.
- Edge Cases: This basic preprocessing function may not handle all edge cases (e.g., contractions, handling numerical data). Depending on your specific use case, additional preprocessing steps may be needed.
This function is a solid starting point for text preprocessing and can be extended or customized as per your specific requirements.
Feature Extraction and Representation
After preprocessing the content, the next step is to extract meaningful features that capture the essence of each piece of content. These features will be used to represent the content as numerical vectors, which can be fed into the clustering algorithm.
Common feature extraction techniques include:
- Term Frequency-Inverse Document Frequency (TF-IDF): Assigns weights to words based on their frequency in a document and rarity across the entire corpus
- Word Embeddings: Represents words as dense vectors that capture semantic relationships between words (e.g., Word2Vec, GloVe)
- Topic Models: Discovers latent topics within the content and represents each document as a distribution over these topics (e.g., Latent Dirichlet Allocation)
Once the features are extracted, the content is represented as numerical vectors. In some cases, the resulting feature vectors may be high-dimensional, which can impact clustering performance. To address this issue, consider applying dimensionality reduction techniques like Principal Component Analysis (PCA) or t-Distributed Stochastic Neighbor Embedding (t-SNE) to reduce the dimensionality while preserving the essential structure of the data.
Handling Multilingual and Multimodal Content
In real-world scenarios, content may come in different languages or modalities (e.g., text, images, videos). To effectively cluster such diverse content, it’s essential to develop strategies to handle multilingual and multimodal data.
For multilingual content, consider the following approaches:
- Language Identification: Detect the language of each piece of content and apply language-specific preprocessing and feature extraction techniques
- Multilingual Embeddings: Use pre-trained multilingual word embeddings (e.g., BERT, XLM) that can represent words from multiple languages in a shared vector space
When dealing with multimodal content, extract relevant features from each modality:
- Text: Apply the preprocessing and feature extraction techniques discussed earlier
- Images: Extract visual features using pre-trained deep learning models (e.g., ResNet, VGG) or handcrafted features like SIFT or SURF
- Videos: Extract frame-level features, motion features, or audio features depending on the relevance to your project
Once features from different modalities are extracted, they can be combined using techniques like concatenation, weighted averaging, or multimodal fusion to create a unified representation for clustering.
By following these steps to prepare your content for clustering, you’ll ensure that your data is clean, informative, and properly represented, setting the stage for applying the chosen clustering algorithm effectively.
Unlocking Meaningful Content Clusters
Content clustering algorithms help you group similar content together based on topics, themes, or semantic similarity. By understanding your project requirements, evaluating similarity measures, and comparing popular algorithms, you can select the most suitable approach for your needs.
Topic modeling techniques like LDA and NMF offer powerful ways to discover latent topics and cluster content accordingly. Semantic clustering using word or sentence embeddings captures the meaning behind your content, enabling more nuanced grouping.
Evaluating cluster quality metrics and validating results with domain expertise ensures your clusters are meaningful and actionable. Iterative refinement helps you arrive at the optimal clustering solution.
Now that you’re armed with this knowledge, it’s time to put it into practice. Start by defining your project goals, gathering your content, and experimenting with different algorithms. As you iterate and refine, you’ll uncover valuable insights and create a well-organized content structure.
Which content clustering technique are you most excited to try first?
